!!!UNTUK MAKALAH BERBENTUK MS.WORD DAPAT DIDOWNLOAD DI LINK BAWAH YA !!!
STATISTIKA PENDIDIKAN
RESUME UJI T, UJI KORELASI DAN UJI ANAVA

Oleh:
Nama : Rizki Juliyantri
Nim : 1532220129
Dosen Pembimbing:
Eri Agusta, M.pd
PROGRAM STUDI PENDIDIKAN BIOLOGI
FAKULTAS ILMU TARBIYAH DAN KEGURUAN
UNIVERSITAS ISLAM NEGERI RADEN FATAH
PALEMBANG
2017
UJI T-TEST
A. Pengertian Uji-T
Uji-T atau T-Test adalah salah satu test statistik yang dipergunakan untuk menguji kebenaran atau kepalsuan hipotesis nol/nihil (Ho) yang menyatakan bahwa di antara dua buah mean sampel yang diambil secara random dari populasi yang sama tidak terdapat perbedaan yang signifikan.
B. Macam- Macam Uji-T
1. One Sample T-Test
Analisis perbandingan satu sampel dikenal dengan Uji-T atau T-Test (one sample t-test) dan uji-Z. Tujuan Uji-T atau Uji-Z adalah untuk mengetahui perbedaan mean variabel yang dihipotesiskan .
Rumus Uji-T :
Apabila standar deviasi diketahui dan n > 30 menggunakan rumus Zhitung sebagai berikut :
Di mana:
Zhitung : harga yang dihitung dan menunjukkan nilai standar
deviasi pada distribusi normal (tabel Z).
x : rata-rata nilai yang diperoleh dari hasil pengumpulan data.
µo : rata-rata nilai yang dihipotesiskan
: rata-rata nilai yang dihipotesiskan
N : jumlah populasi penelitian
Apabila standar deviasi sampel tidakhitung dik sebagai berikut :
Thitung : harga yang dihitung dan menunjukkan nilai standar deviasi pada
distribusi t (tabel t).
x : harga yang dihitung dan menunjukkan nilai standar deviasi pada
distribusi t (tabel t).
µo : rata-rata nilai yang dihipotesiskan
SD : standar deviasi sampel yang telah diketahui
N : jumlah sampel penelitian
Independent Sample T-Test
Uji ini untuk mengetahui perbedaan ratarata dua populasi/kelompk data yang independen.
Uji T independen ini memiliki asumsi/syarat yang mesti dipenuhi, yaitu :
Datanya berdistribusi normal.
Kedua kelompok data independen (bebas)
variabel yang dihubungkan berbentuk numerik dan kategorik (dengan hanya 2 kelompok)
Paired Sample T-Test
Uji –t berpasangan (paired t-test) adalah salah satu metode pengujian hipotesis dimana data yang digunakan tidak bebas (berpasangan). Ciri-ciri yang paling sering ditemui pada kasus yang berpasangan adalah satu individu (objek penelitian) dikenai 2 buah perlakuan yang berbeda. Walaupun menggunakan individu yang sama, peneliti tetap memperoleh 2 macam data sampel, yaitu data dari perlakuan pertama dan data dari perlakuan kedua.
C. Contoh Kasus
Menggunakan analisis perbandingan satu sampel dikenal dengan Uji-T atau T-Test (one sample t-test)
Hasil rapat koordinasi pimpinan perguruan tinggi swasta di lingkungan kopertis wilayah X menduga bahwa kualitas mengajar dosen tahun 2013 tidak sama dengan 70% dari rata-rata nilai ideal. Dengan pernyataan tersebut, ditindaklanjuti atau dibuktikan oleh Balitbang Dikti dengan suatu penelitian di berbagai kota di wilayah kopertis X. Kemudian disebar kepada 20 dosen untuk mengisi angket yang isinya mengenai kualitas mengajar pada tahun 2013. Jumlah pertanyaan angket penelitian 15 item dengan instrumen diberi skala nilai : 4 = sangat baik, 3 = baik, 2 = cukup baik dan 1 = kurang baik. Adapun taraf signifkansi α= 0,05.
Data diperoleh sebagai berikut :
Langkah-langkah One Sample t-tes dengan SPSS:
1. Input data di atas ke dalam SPSS
2. Pada kolom Name ketik Kulaitas.
3. Pada kolom Decimals angka ganti menjadi 0.
4. Pada kolom Label isikan Kualitas Mengajar pada kualitas.
5. Pada kolom Align isikan Center.
6. Pada kolom Measure isikan Ordinal.
Untuk kolom-kolom lainnya biarkan saja (isian default).

Klik tab sheet [Variable View] pada SPSS data editor dan ketik/copy data sebagai berikut:

Selanjutanya klik [Analyze] > [Compare Means] > [One-Sample T Test].

Akan muncul kotak dialog One-Sample T Test, masukan variabel kualitas mengajar pada kotak Test Variables di sebelah kanan.
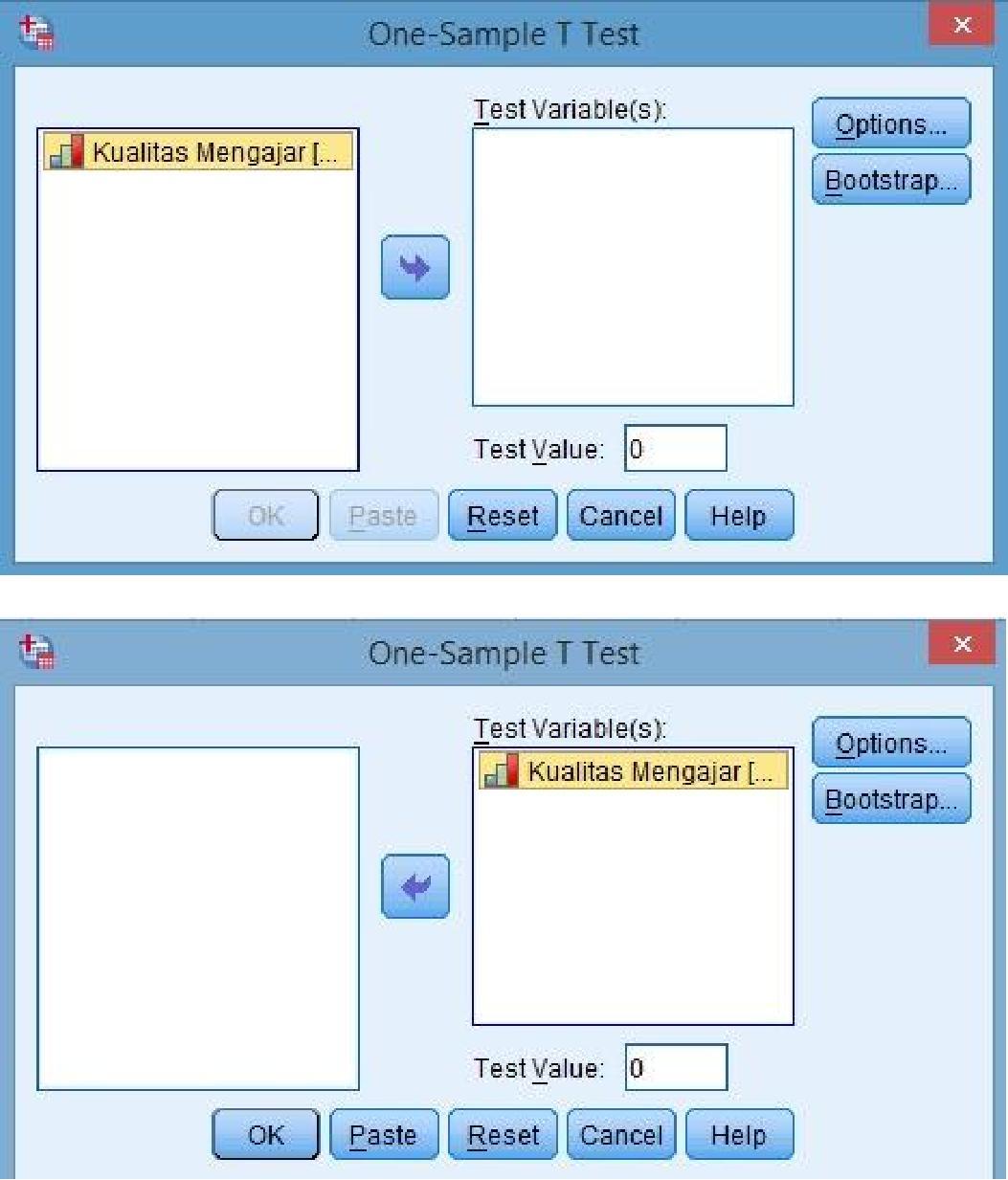
Klik tab Options maka akan muncul kotak dialog One-Sample T Test: Options. Pastikan tingkat kepercayaan adalah 95%, kemudian klik Continue. Klik [OK].

Muncul output SPSS viewer menampilkan hasil sebagai berikut:
One-Sample Statistics
Tabel One-Sample Statistics memaparkan nilai statistik variabel Kualitas Mengajar sebagai berikut: jumlah sampel (n) = 20, rata-rata kualitas mengajar 58,35, standar deviasi 2,961 dan Ltd eror Man = 0,662.
One-Sample Test
Sebelum menguji hipotesis, kita perlu memahami kriteria pengujian hipotesisnya. Selain dengan membandingkan nilai t hitung dengan nilai pada tabel t, di SPSS juga bisa menggunakan nilai Sig, jika Sig > 0,05 maka Ho diterima dan jika Sig < 0,05 maka Ho ditolak.
Dari contoh di atas hipotesisnya adalah:
Ho : rata-rata kualitas mengajar 70%.
H1 : rata-rata kualitas mengajar tidak sama dengan 70%.
Pada output diketahui Sig (2-tailled) = 0,000 < 0,05 maka Ho ditolak, artinya kualitas mengajar dosen tidak sama dengan 70%. Bisa juga dengan membandingkan t hitung dengan nilai t tabel.
UJI KORELASI
A. Pengertian korelasi
Korelasi adalah istilah statistik yang menyatakan derajat hubungan linier (searah bukan timbal balik) antara dua variabel atau lebih. artinya sifat hubungan variabel satu dengan variabel lainnya tidak jelas mana variabel sebab dan mana variabel akibat. Sebaliknya, jika hubungan tersebut menunjukkan sifat sebab akibat maka korelasinya dikatakan kausal, artinya jika variabel yang satu merupakan sebab, maka variabel lainnya merupakan akibat.
B. Macam-macam Teknik Korelasi
1. Product Moment Pearson : Kedua variabelnya berskala interval
2. Rank Spearman : Kedua variabelnya berskala ordinal
3. Point Serial : Satu berskala nominal sebenarnya dan satu
Berskala interval
4. Biserial : Satu berskala nominal buatan dan satu berskala
interval
5. Koefisien kontingensi : Kedua varibelnya berskala nominal
C. Contoh Kasus
Untuk data yang berskala interval dan atau rasio (bersifat kuantitatif/parametrik) tipe analisis korelasi yang digunakan adalah Pearson Correlation atau istilah lainnya adalah Product Moment Correlation. Sedangkan untuk yang berskala ordinal kita gunakan Spearman Correlation (Statistik Non-Parametrik).
Kedua variabel yang ada yaitu pengetahuan kewarganegaraan dan tingkat partisipasi politik umumnya belum memiliki standar yang baku dalam skala nilainya. Biasanya untuk mendapatkan nilai-nilai bagi variabel-variabel tersebut kita terlebih dahulu melakukan pengukuran kepada sejumlah responden mengenai tingkat pengetahuannya tentang kewarganegaraan dan tingkat partisipasi politiknya, biasanya kita akan menyebarkan angket yang berisi sejumlah daftar pertanyaan atau pernyataan yang akan mengukur sejauh mana level pengetahuan kewarganegaraannya dan tingkat partisipasi politiknya, baik level pengetahuan kewarganegaraan dan tingkat partisipasi politik keduanya merupakan konsep yang berkaitan dengan perilaku seorang manusia. Seperti telah diulas dalam modul sebelumnya, para peneliti ilmu sosial umumnya menggunakan Skala Likert guna mengukur persepsi atau perilaku sosial. Maka biasanya data yang akan kita dapatkan dari hasil survey/penyebaran angket yang mengukur tingkat pengetahuan kewarganegaraan seseorang dan tingkat partisipasi politiknya akan berskala ordinal. Misalkan untuk mengukur pengetahuan seseorang dibuatkan instrumen yang terdiri atas 6 butir pertanyaan guna mengukur pengetahuannya tentang kewarganegaraan yang diberikan kepada 5 orang responden (A,B,C,D dan E). Dari lima orang responden akan memiliki jawaban atas angket yang diberikan sebagai berikut.
Maka nilai-nilai jawaban tersebut terlebih dahulu harus di transformasikan ke dalam data interval. Misalkan hasilnya (Succesive Interval-nya) diperoleh sebagai berikut:
Lalu untuk mendapatkan skor tiap-tiap responden untuk menentukkan tingkat pengetahuan kewarganegaraan yang dimilikinya digunakan rumus tertentu (caranya dibahas pada topik berikutnya). Skor tingkat pengetahuan kewarganegaraan dari kelima responden tersebut akhirnya, misalnya diperoleh sebagai berikut.
Tabel Skor Reponden untuk
Tingkat Pengetahuan Kewarganegaraan
Selanjutnya hal yang sama dilakukan pula untuk mendapatkan skor mengenai tingkat partisipasi politiknya, sehingga misalnya akhirnya diperoleh data sebagai berikut.
Tabel Data Lengkap
Langkah-langkah Product Moment Pearson menggunakan SPSS sebagai berikut:
Buat file dengan nama korelasi1.sav, berkenaan dengan data lengkap di atas. Misalkan variabel Skor Tingkat Pengetahuan Kewarganegaraan namai Citizenship dan Skor Tingkat Partisipasi Politik namai Participation, hasilnya seperti berikut.
pilih menu Analyze. Kemudian pilih submenu Correlate, dan pilih bivariate. Maka akan tampak di layar tampilan seperti gambar berikut:

Selanjutnya adalah mengisi menu-menu yang ada sebagai berikut:
a. Variable yang akan dikorelasikan, pilih Citizenship dan Participation
b. Correlation Coeffitients atau alat hitung koefisien korelasi. Pilih Pearson.
c. Test of Significance yang akan digunakan, pilih Two-tailed untuk uji dua sisi.
d. Flag significant correlations pilih untuk diaktifkan, dengan cara mengkliknya.
e. Kemudian tekan tombol Options, hingga tampak di layar tampilan seperti ini.

d. Lalu pada pilihan statistics abaikan saja.
e. Pada menu missing values, pilih Exclude case pairwise untuk aktif.
Selanjutnya tekan Continue.
f. Tekan OK untuk mengakhiri pengisisian prosedur analisis. Selanjutnya
SPSS melakukan pekerjaan analisis yang hasilnya dapat terlihat pad
bagian output berikut ini.
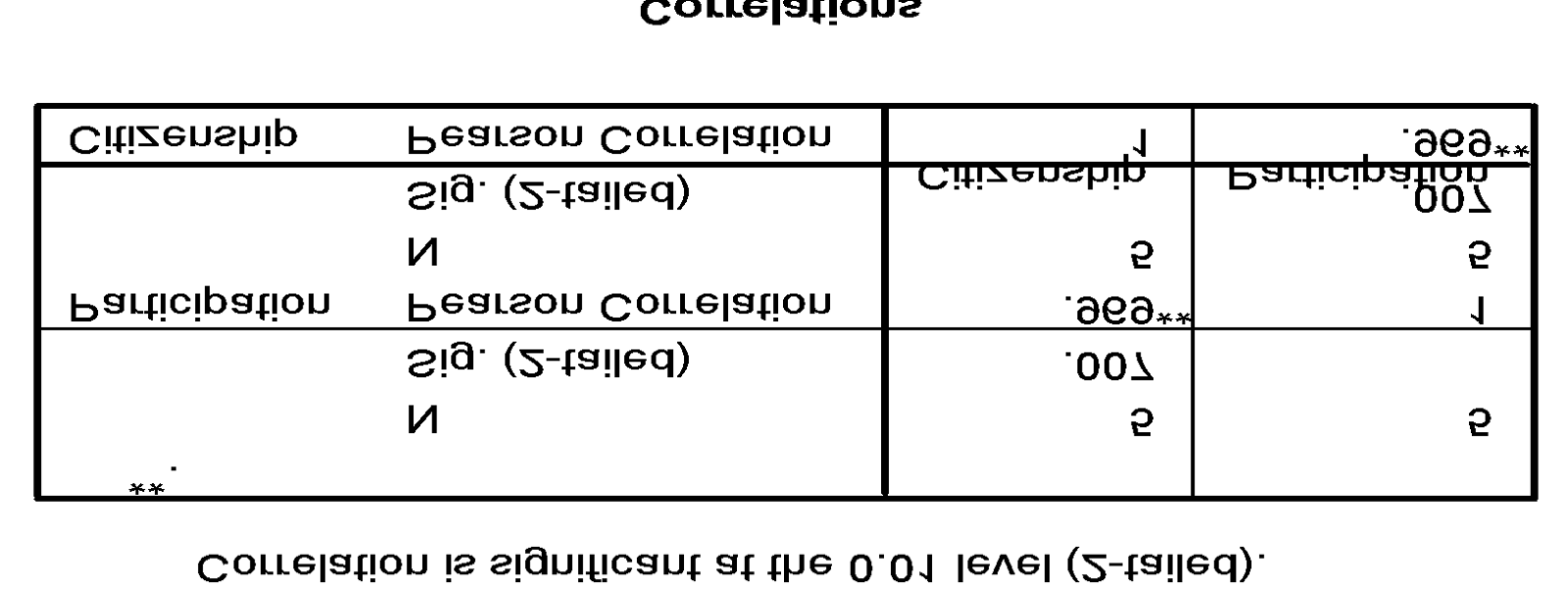
Analisis Output
Arti Angka Korelasi (Lihat Pearson Correlation)
Ada dua hal dalam penafsiran korelasi, yaitu tanda ‘+” atau ‘-“ yang berhubungan dengan arah korelasi, serta kuat tidaknya korelasi.
Korelasi antara Citizenship dengan Participation, didapat angka +0,969 (tanda “+” disertakan karena tidak ada tanda “-“ pada output, jadi otomatis positif). Hal ini berarti :
Arah korelasi positif, artinya semakin tinggi tingkat pengetahuan kewarganegaraan seseorang maka partisipasi politiknya cenderung semakin besar. Demikian pula sebaliknya.
Besaran korelasi (0,969) yang > 0,5, berarti tingkat pengetahuan kewarganegaraan seseorang berkorelasi KUAT dengan partisipasi politiknya.
2. Signifikansi Hasil Korelasi (lihat Sig. (2-tailed))
Bila kita hendak merumuskan hipotesis bahwa antara dua variabel, yaitu tingkat pengetahuan kewarganegaraan seseorang dengan partisipasi politiknya memiliki hubungan (korelasi), maka secara statistik dapat dinyatakan seperti berikut:
H0:Tidak ada hubungan (korelasi) antara dua variabel
Hi: Ada hubungan (korelasi) antara dua variabel
Maka bila kita ingin menguji hipotesis ini, kita misalnya dapat menguji dengan melakukan uji dua sisi. Dasar pengambilan keputusannya adalah dengan dasar probabilitas sebagai berikut:
Jika probabilitas > 0,05 (atau 0,01) maka Ho diterima
Jika probabilitas < 0,05 (atau 0,01) maka Ho ditolak
Catatan: 0,05 atau 0,01 adalah tergantung pilihan kita.
Keputusan pada contoh kasus yang kita miliki pada keterangan Sig. (2-tailed) diperoleh angka probailitasnya 0,007 maka kedua variabel tersebut memang SECARA NYATA berkorelasi. Hal ini bisa dilihat juga dari adanya tanda ** pada angka korelasi.
3. Jumlah Data yang Berkorelasi
Dapat dilihat dari dari nilai N, karena tidak ada data yang hilang, maka data yang diproses adalah 5.
UJI ANAVA
A. Pengertian Analisis Variansi (ANAVA)
Analisis variansi adalah suatu prosedur untuk uji perbedaan mean beberapa populasi. Konsep analisis variansi didasarkan pada konsep distribusi F dan biasanya dapat diaplikasikan untuk berbagai macam kasus maupun dalam analisis hubungan antara berbagai varabel yang diamati. Dalam perhitungan statistik, analisis variansi sangat dipengaruhi asumsi-asumsi yang digunakan seperti kenormalan dari distribusi, homogenitas variansi dan kebebasan dari kesalahan.
B. Macam- Macam Analisis Varian (ANAVA)
Analisis Varian Satu Jalan (One Way ANAVA)
Analisis varian atau nalysis of variance (Anova) biasa digunakan untuk mengui perbandingan. Penelitian yang ingin menguji hipotesis komparasi (perbandingan) pada umumnya menggunakan alat uji analisis varian. Karena itu analisis varian digunakan untuk menguji hipotesis komparasi rata-rata k sampel.
Analisis Varian Dua Jalan (Two Way ANAVA)
Analisis varian dua jalan merupakan teknik analisis yang digunakan untuk menentukan apakah perbedaan atau variasi nilai suatu avriabel terikat disebabkan oleh atau tergantung pada perbedaan (variasi) nilai pada dua variabel bebas. Pada analisis varian dua jalan terdapat empat komponen varian niali yang harus dipisah-pisahkan karena memiliki makna yang berbeda, yaitu :
Komponen explained varian untuk seluruh variabel bebas (X1+X2)
Komponen explained varian variabel bebas X1 saja
Komponen explained varian variabel bebas X2 saja
Komponen un explained varian.
Besaran angka yang dihasilkan oelh SPSS digunakan untuk:
Menentukan signifikan secara umum
Menentukan signifikan per pasangan
Menentukan besaran masing-masing komponen varian.
C. Contoh Kasus
Menggunakan analisis varian satu jalan dilakukan untuk variabel terikat (y) secara bersambung untuk semua kelompok. Kelompok dikenali dari variabel bebas (x). Sebagai contoh, akan dianalisis data untuk menguji hipotesis: Terdapat perbedaan hasil belajar Bahasa Inggris antara siswa yang mengikuti pembelajaran dengan media audio-video, multi media, dan hipermedia. Pada siswa yang berkepribadian introvert, terdapat perbedaan hasil belajar Bahasa Inggris antara siswa yang mengikuti pembelajaran dengan media audio -video, multi media, dan hipermedia.Pada siswa yang berkepribadian ekstrovert, terdapat perbedaan hasil belajar Bahasa Inggris antara siswa yang mengikuti pembelajaran dengan media audio-video, multi media, dan hipermedia. Terdapat pengaruh interaksi antara jenis media pembelajaran dan kepribadian siswa terhadap hasil belajar Bahasa Inggris.
Data hasil penelitian adalah sebagi berikut.
Apabila dibuat dalam bentuk tabel kerja, maka tabel di atas akan tampa
seperti di bawah ini.
Langkah-langkah Analisis Varian Satu Jalan (One Way ANAVA)
dengan SPSS:
Setelah dimasukkan ke form SPSS, data dalam form SPSS akan tampak sebagai berikut.
Analisis Data
Menu ANAVA pada SPSS terletak di General Linear Model, dengan langkah- langkah seperti berikut.
Analyze General Linear model Univariate

Apabila menu tersebut sudah dipilih, maka akan tampak kotak dialog. Pindahkan y ke dependent variabel dan x ke fixed faktor(s), seperti bagan berikut

Selanjutnya dipilih menu- menu yang lain untuk melengkapi analisis yang diperlukan. Misalnya, jika diperlukan uji lanjut, maka pilih menu Post Hoc… sehingga muncul menu dialog seperti di bawah ini.
Berikan tanda centang (v) pada kotak di depan nama uji lanjut yang dipilih. Misalnya, pada contoh di atas dipilih uji Tukey dan Uji Scheffe. Setelah itu, pilih menu Continue. Berikutnya, pilih menu-menu lain yang dipandang perlu untuk melengkapi analisis. Jika semua menu yang diperlukan sudah dipilih, maka selanjutnya pilih OK, sehingga muncul hasil analisis. Hasil analisis yang diperlukan adalah seperti tampak pada bagan berikut.
Tests of Between-Subjects Effects
Dependent Variable: Y
a R Squared = .422 (Adjusted R Squared = .342)
Hasil analisis menunjukkan bahwa harga F untuk A besarnya 9,559 dengan signifikansi 0,000. Untuk menginterpretasikan hasil analisis di atas dilakukan mekanisme sebagai berikut.
Tetapkan signifikansi, misalnya a=0,05.
Bandingkan a dengan signifikansi yang diperoleh (sig). Apabila a < sig., maka H1 diterima, sebaliknya bila a sig., maka H0 diterima.
Ternyata hasil analisis menunjukkan bahwa sig. besarnya 0,000 lebih kecil daripada a = 0,05. Dengan demikian H0 ditolak dan H1 diterima. Jadi kesimpulannya, terdapat perbedaan hasil belajar Bahasa Inggris antara siswa yang mengikuti pembelajaran dengan media audio-video, multi media, dan hipermedia.
Komentar
Posting Komentar